Advanced usage¶
Customize resource options¶
By default ModelResource introspects model
fields and creates Field attributes with an
appropriate Widget for each field.
Fields are generated automatically by introspection on the declared model class. The field defines the relationship between the resource we are importing (for example, a csv row) and the instance we want to update. Typically, the row data will map onto a single model instance. The row data will be set onto model instance attributes (including instance relations) during the import process.
In a simple case, the name of the row headers will map exactly onto the names of the model attributes, and the import process will handle this mapping. In more complex cases, model attributes and row headers may differ, and we will need to declare explicitly declare this mapping. See Model relations for more information.
Declare import fields¶
You can optionally use the fields declaration to affect which fields are handled during import.
To affect which model fields will be included in a resource, use the fields option to whitelist fields:
class BookResource(resources.ModelResource):
class Meta:
model = Book
fields = ('id', 'name', 'price',)
Or the exclude option to blacklist fields:
class BookResource(resources.ModelResource):
class Meta:
model = Book
exclude = ('imported', )
An explicit order for exporting fields can be set using the export_order
option:
class BookResource(resources.ModelResource):
class Meta:
model = Book
fields = ('id', 'name', 'author', 'price',)
export_order = ('id', 'price', 'author', 'name')
Model relations¶
When defining ModelResource fields it is
possible to follow model relationships:
class BookResource(resources.ModelResource):
class Meta:
model = Book
fields = ('author__name',)
This example declares that the Author.name value (which has a foreign key relation to Book) will appear in the
export.
Note that declaring the relationship using this syntax sets field as readonly, meaning this field will be skipped
when importing data. To understand how to import model relations, see Importing model relations.
Explicit field declaration¶
We can declare fields explicitly to give us more control over the relationship between the row and the model attribute.
In the example below, we use the attribute kwarg to define the model attribute, and column_name to define the
column name (i.e. row header):
from import_export.fields import Field
class BookResource(resources.ModelResource):
published = Field(attribute='published', column_name='published_date')
class Meta:
model = Book
See also
- Fields
- Available field types and options.
Custom workflow based on import values¶
You can extend the import process to add workflow based on changes to persisted model instances.
For example, suppose you are importing a list of books and you require additional workflow on the date of publication. In this example, we assume there is an existing unpublished book instance which has a null ‘published’ field.
There will be a one-off operation to take place on the date of publication, which will be identified by the presence of the ‘published’ field in the import file.
To achieve this, we need to test the existing value taken from the persisted instance (i.e. prior to import
changes) against the incoming value on the updated instance.
Both instance and original are attributes of RowResult.
You can override the after_import_row() method to check if the
value changes:
class BookResource(resources.ModelResource):
def after_import_row(self, row, row_result, **kwargs):
if getattr(row_result.original, "published") is None \
and getattr(row_result.instance, "published") is not None:
# import value is different from stored value.
# exec custom workflow...
class Meta:
model = Book
store_instance = True
Note
- The
originalattribute will be null ifskip_diffis True. - The
instanceattribute will be null ifstore_instanceis False.
Field widgets¶
A widget is an object associated with each field declaration. The widget has two roles:
- Transform the raw import data into a python object which is associated with the instance (see
clean()). - Export persisted data into a suitable export format (see
render()).
There are widgets associated with character data, numeric values, dates, foreign keys. You can also define your own widget and associate it with the field.
A ModelResource creates fields with a default widget for a given field type via
instrospection. If the widget should be initialized with different arguments, this can be done via an explicit
declaration or via the widgets dict.
For example, the published field is overridden to use a different date format. This format will be used both for
importing and exporting resource:
class BookResource(resources.ModelResource):
published = Field(attribute='published', column_name='published_date',
widget=DateWidget(format='%d.%m.%Y'))
class Meta:
model = Book
Alternatively, widget parameters can be overridden using the widgets dict declaration:
class BookResource(resources.ModelResource):
class Meta:
model = Book
widgets = {
'published': {'format': '%d.%m.%Y'},
}
See also
- Widgets
- available widget types and options.
Importing model relations¶
If you are importing data for a model instance which has a foreign key relationship to another model then import-export can handle the lookup and linking to the related model.
Foreign Key relations¶
ForeignKeyWidget allows you to declare a reference to a related model. For example, if we are importing a ‘book’
csv file, then we can have a single field which references an author by name.
id,title,author
1,The Hobbit, J. R. R. Tolkien
We would have to declare our BookResource to use the author name as the foreign key reference:
from import_export import fields, resources
from import_export.widgets import ForeignKeyWidget
class BookResource(resources.ModelResource):
author = fields.Field(
column_name='author',
attribute='author',
widget=ForeignKeyWidget(Author, field='name'))
class Meta:
model = Book
fields = ('author',)
By default, ForeignKeyWidget will use ‘pk’ as the lookup field, hence we have to pass ‘name’ as the lookup field.
This relies on ‘name’ being a unique identifier for the related model instance, meaning that a lookup on the related
table using the field value will return exactly one result.
This is implemented as a Model.objects.get() query, so if the instance in not uniquely identifiable based on the
given arg, then the import process will raise either DoesNotExist or MultipleObjectsReturned errors.
See also Creating non existent relations.
Refer to the ForeignKeyWidget documentation for more detailed information.
Many-to-many relations¶
ManyToManyWidget allows you to import m2m references. For example, we can import associated categories with our
book import. The categories refer to existing data in a Category table, and are uniquely referenced by category
name. We use the pipe separator in the import file, which means we have to declare this in the ManyToManyWidget
declaration.
id,title,categories
1,The Hobbit,Fantasy|Classic|Movies
class BookResource(resources.ModelResource):
categories = fields.Field(
column_name='categories',
attribute='categories',
widget=widgets.ManyToManyWidget(Category, field='name', separator='|')
)
class Meta:
model = Book
Creating non existent relations¶
The examples above rely on the relation data being present prior to the import. It is a common use-case to create the data if it does not already exist. It is possible to achieve this as follows:
class BookResource(resources.ModelResource):
def before_import_row(self, row, **kwargs):
author_name = row["author"]
Author.objects.get_or_create(name=author_name, defaults={"name": author_name})
class Meta:
model = Book
The code above can be adapted to handle m2m relationships.
You can also achieve similar by subclassing the widget clean() method to
create the object if it does not already exist.
Customize relation lookup¶
The ForeignKeyWidget and ManyToManyWidget widgets will look for relations by searching the entire relation
table for the imported value. This is implemented in the get_queryset()
method. For example, for an Author relation, the lookup calls Author.objects.all().
In some cases, you may want to customize this behaviour, and it can be a requirement to pass dynamic values in.
For example, suppose we want to look up authors associated with a certain publisher id. We can achieve this by passing
the publisher id into the Resource constructor, which can then be passed to the widget:
class BookResource(resources.ModelResource):
def __init__(self, publisher_id):
super().__init__()
self.fields["author"] = fields.Field(
attribute="author",
column_name="author",
widget=AuthorForeignKeyWidget(publisher_id),
)
The corresponding ForeignKeyWidget subclass:
class AuthorForeignKeyWidget(ForeignKeyWidget):
model = Author
field = 'name'
def __init__(self, publisher_id, **kwargs):
super().__init__(self.model, field=self.field, **kwargs)
self.publisher_id = publisher_id
def get_queryset(self, value, row, *args, **kwargs):
return self.model.objects.filter(publisher_id=self.publisher_id)
Then if the import was being called from another module, we would pass the publisher_id into the Resource:
>>> resource = BookResource(publisher_id=1)
If you need to pass dynamic values to the Resource from an Admin integration, refer to How to dynamically set resource values.
Django Natural Keys¶
The ForeignKeyWidget also supports using Django’s natural key functions. A
manager class with the get_by_natural_key function is required for importing
foreign key relationships by the field model’s natural key, and the model must
have a natural_key function that can be serialized as a JSON list in order to
export data.
The primary utility for natural key functionality is to enable exporting data that can be imported into other Django environments with different numerical primary key sequences. The natural key functionality enables handling more complex data than specifying either a single field or the PK.
The example below illustrates how to create a field on the BookResource that
imports and exports its author relationships using the natural key functions
on the Author model and modelmanager.
The resource _meta option use_natural_foreign_keys enables this setting
for all Models that support it.
from import_export.fields import Field
from import_export.widgets import ForeignKeyWidget
class AuthorManager(models.Manager):
def get_by_natural_key(self, name):
return self.get(name=name)
class Author(models.Model):
objects = AuthorManager()
name = models.CharField(max_length=100)
birthday = models.DateTimeField(auto_now_add=True)
def natural_key(self):
return (self.name,)
# Only the author field uses natural foreign keys.
class BookResource(resources.ModelResource):
author = Field(
column_name = "author",
attribute = "author",
widget = ForeignKeyWidget(Author, use_natural_foreign_keys=True)
)
class Meta:
model = Book
# All widgets with foreign key functions use them.
class BookResource(resources.ModelResource):
class Meta:
model = Book
use_natural_foreign_keys = True
Read more at Django Serialization.
Create or update model instances¶
When you are importing a file using import-export, the file is processed row by row. For each row, the import process is going to test whether the row corresponds to an existing stored instance, or whether a new instance is to be created.
If an existing instance is found, then the instance is going to be updated with the values from the imported row, otherwise a new row will be created.
In order to test whether the instance already exists, import-export needs to use a field (or a combination of fields) in the row being imported. The idea is that the field (or fields) will uniquely identify a single instance of the model type you are importing.
To define which fields identify an instance, use the import_id_fields meta attribute. You can use this declaration
to indicate which field (or fields) should be used to uniquely identify the row. If you don’t declare
import_id_fields, then a default declaration is used, in which there is only one field: ‘id’.
For example, you can use the ‘isbn’ number instead of ‘id’ to uniquely identify a Book as follows:
class BookResource(resources.ModelResource):
class Meta:
model = Book
import_id_fields = ('isbn',)
fields = ('isbn', 'name', 'author', 'price',)
Note
If setting import_id_fields, you must ensure that the data can uniquely identify a single row. If the chosen
field(s) select more than one row, then a MultipleObjectsReturned exception will be raised. If no row is
identified, then DoesNotExist exception will be raised.
Handling duplicate data¶
If an existing instance is identified during import, then the existing instance will be updated, regardless of whether
the data in the import row is the same as the persisted data or not. You can configure the import process to skip the
row if it is duplicate by using setting skip_unchanged.
If skip_unchanged is enabled, then the import process will check each defined import field and perform a simple
comparison with the existing instance, and if all comparisons are equal, then the row is skipped. Skipped rows are
recorded in the row Result object.
You can override the skip_row() method to have full control over the skip row implementation.
Also, the report_skipped option controls whether skipped records appear in the import
Result object, and whether skipped records will show in the import preview page in the Admin UI:
class BookResource(resources.ModelResource):
class Meta:
model = Book
skip_unchanged = True
report_skipped = False
fields = ('id', 'name', 'price',)
See also
How to set a value on all imported instances prior to persisting¶
You may have a use-case where you need to set the same value on each instance created during import. For example, it might be that you need to set a value read at runtime on all instances during import.
You can define your resource to take the associated instance as a param, and then set it on each import instance:
class BookResource(ModelResource):
def __init__(self, publisher_id):
self.publisher_id = publisher_id
def before_save_instance(self, instance, using_transactions, dry_run):
instance.publisher_id = self.publisher_id
class Meta:
model = Book
See also How to dynamically set resource values.
Advanced data manipulation on export¶
Not all data can be easily extracted from an object/model attribute.
In order to turn complicated data model into a (generally simpler) processed
data structure on export, dehydrate_<fieldname> method should be defined:
from import_export.fields import Field
class BookResource(resources.ModelResource):
full_title = Field()
class Meta:
model = Book
def dehydrate_full_title(self, book):
book_name = getattr(book, "name", "unknown")
author_name = getattr(book.author, "name", "unknown")
return '%s by %s' % (book_name, author_name)
In this case, the export looks like this:
>>> from app.admin import BookResource
>>> dataset = BookResource().export()
>>> print(dataset.csv)
full_title,id,name,author,author_email,imported,published,price,categories
Some book by 1,2,Some book,1,,0,2012-12-05,8.85,1
It is also possible to pass a method name in to the Field() constructor. If this method
name is supplied, then that method
will be called as the ‘dehydrate’ method.
Filtering querysets during export¶
You can use filter_export() to filter querysets
during export. See also Customize admin export forms.
Signals¶
To hook in the import-export workflow, you can connect to post_import,
post_export signals:
from django.dispatch import receiver
from import_export.signals import post_import, post_export
@receiver(post_import, dispatch_uid='balabala...')
def _post_import(model, **kwargs):
# model is the actual model instance which after import
pass
@receiver(post_export, dispatch_uid='balabala...')
def _post_export(model, **kwargs):
# model is the actual model instance which after export
pass
Admin integration¶
One of the main features of import-export is the support for integration with the Django Admin site. This provides a convenient interface for importing and exporting Django objects.
Please install and run the example application to become familiar with Admin integration.
Integrating import-export with your application requires extra configuration.
Admin integration is achieved by subclassing
ImportExportModelAdmin or one of the available
mixins (ImportMixin,
ExportMixin,
ImportExportMixin):
# app/admin.py
from .models import Book
from import_export.admin import ImportExportModelAdmin
class BookAdmin(ImportExportModelAdmin):
resource_classes = [BookResource]
admin.site.register(Book, BookAdmin)
Once this configuration is present (and server is restarted), ‘import’ and ‘export’ buttons will be presented to the user. Clicking each button will open a workflow where the user can select the type of import or export.
You can assign multiple resources to the resource_classes attribute. These resources will be presented in a select
dropdown in the UI.
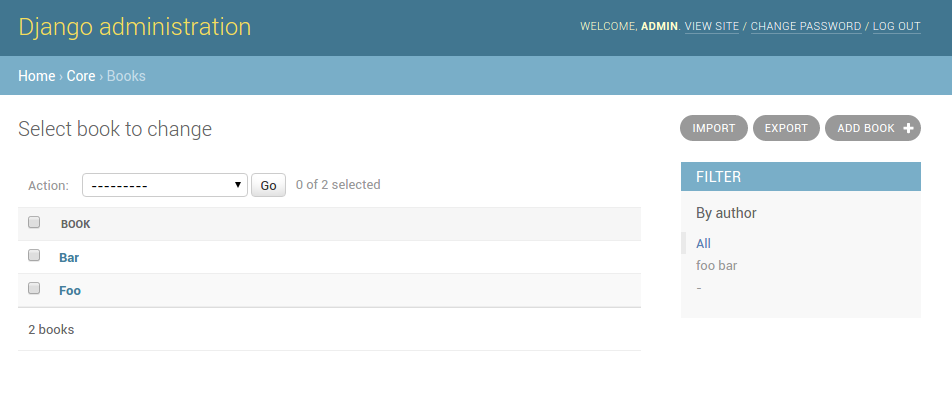
A screenshot of the change view with Import and Export buttons.
Exporting via admin action¶
Another approach to exporting data is by subclassing
ExportActionModelAdmin which implements
export as an admin action. As a result it’s possible to export a list of
objects selected on the change list page:
# app/admin.py
from import_export.admin import ExportActionModelAdmin
class BookAdmin(ExportActionModelAdmin):
pass
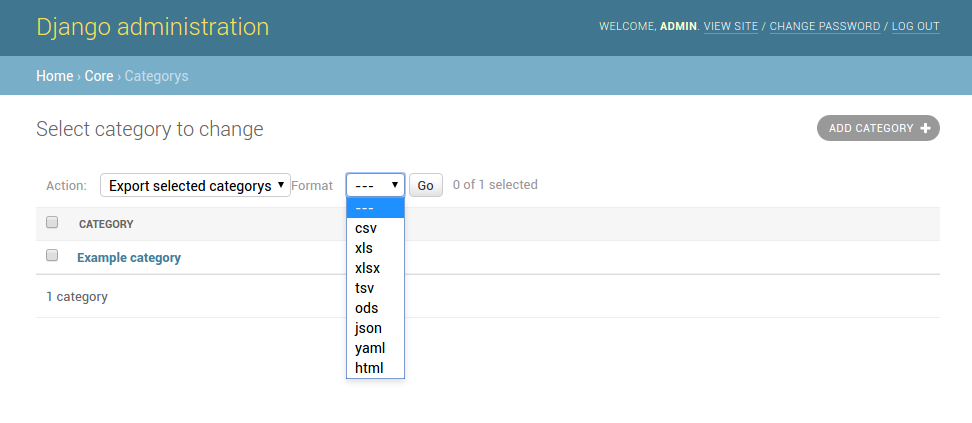
A screenshot of the change view with Import and Export as an admin action.
Note that to use the ExportMixin or
ExportActionMixin, you must declare this mixin
before admin.ModelAdmin.
Importing¶
It is also possible to enable data import via standard Django admin interface.
To do this subclass ImportExportModelAdmin or use
one of the available mixins, i.e. ImportMixin, or
ImportExportMixin.
By default, import is a two step process, though it can be configured to be a single step process (see IMPORT_EXPORT_SKIP_ADMIN_CONFIRM).
The two step process is:
- Select the file and format for import.
- Preview the import data and confirm import.
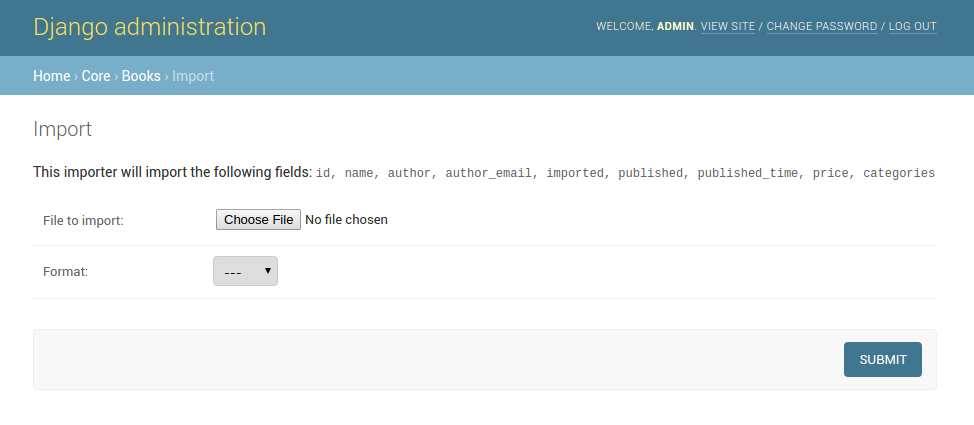
A screenshot of the import view.
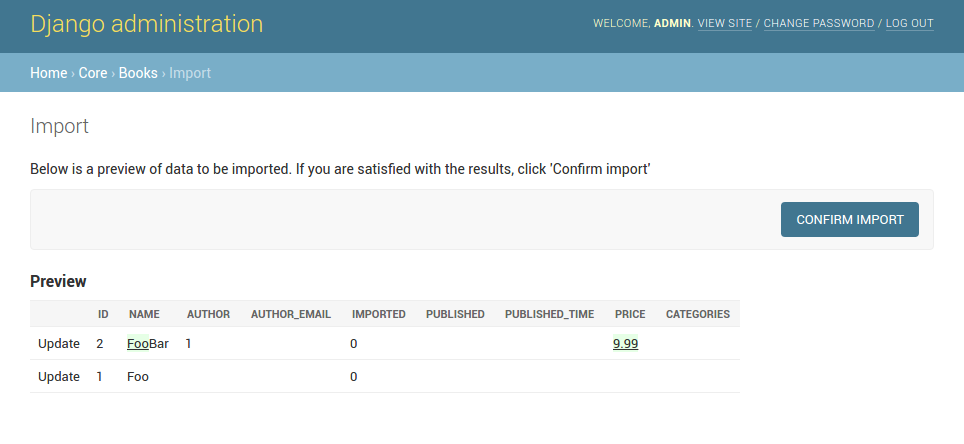
A screenshot of the confirm import view.
Import confirmation¶
To support import confirmation, uploaded data is written to temporary storage after step 1 (choose file), and read back for final import after step 2 (import confirmation).
There are three mechanisms for temporary storage.
- Temporary file storage on the host server (default). This is suitable for development only. Use of temporary filesystem storage is not recommended for production sites.
- The Django cache.
- Django storage.
To modify which storage mechanism is used, please refer to the setting IMPORT_EXPORT_TMP_STORAGE_CLASS.
Temporary resources are removed when data is successfully imported after the confirmation step.
Your choice of temporary storage will be influenced by the following factors:
- Sensitivity of the data being imported.
- Volume and frequency of uploads.
- File upload size.
- Use of containers or load-balanced servers.
Warning
If users do not complete the confirmation step of the workflow, or if there are errors during import, then temporary resources may not be deleted. This will need to be understood and managed in production settings. For example, using a cache expiration policy or cron job to clear stale resources.
Customize admin import forms¶
It is possible to modify default import forms used in the model admin. For
example, to add an additional field in the import form, subclass and extend the
ImportForm (note that you may want to also
consider ConfirmImportForm as importing is a
two-step process).
To use your customized form(s), change the respective attributes on your
ModelAdmin class:
For example, imagine you want to import books for a specific author. You can
extend the import forms to include author field to select the author from.
Note
Importing an E-Book using the example application demonstrates this.
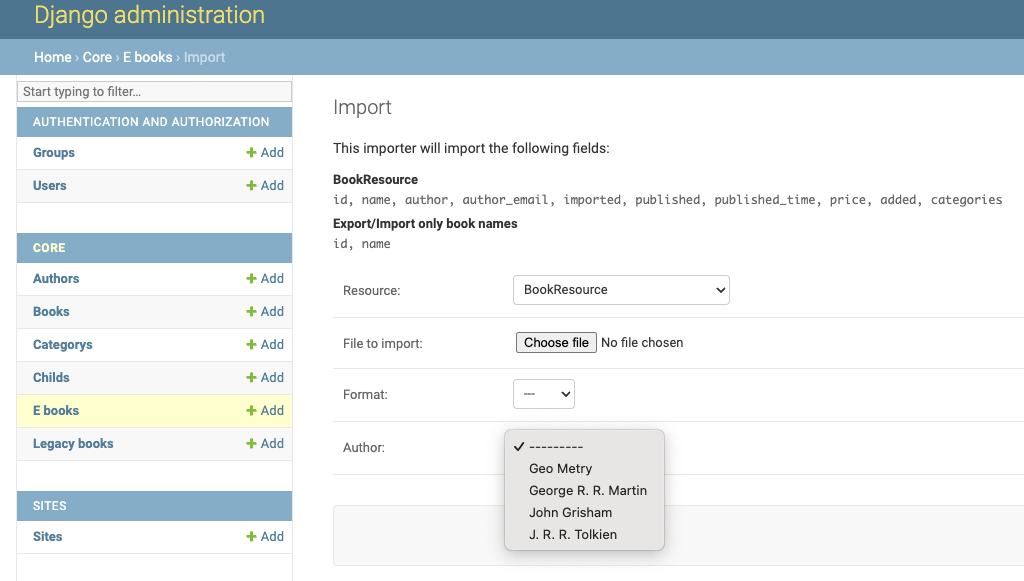
A screenshot of a customized import view.
Customize forms (for example see tests/core/forms.py):
class CustomImportForm(ImportForm):
author = forms.ModelChoiceField(
queryset=Author.objects.all(),
required=True)
class CustomConfirmImportForm(ConfirmImportForm):
author = forms.ModelChoiceField(
queryset=Author.objects.all(),
required=True)
Customize ModelAdmin (for example see tests/core/admin.py):
class CustomBookAdmin(ImportMixin, admin.ModelAdmin):
resource_classes = [BookResource]
import_form_class = CustomImportForm
confirm_form_class = CustomConfirmImportForm
def get_confirm_form_initial(self, request, import_form):
initial = super().get_confirm_form_initial(request, import_form)
# Pass on the `author` value from the import form to
# the confirm form (if provided)
if import_form:
initial['author'] = import_form.cleaned_data['author']
return initial
admin.site.register(Book, CustomBookAdmin)
To further customize the import forms, you might like to consider overriding the following
ImportMixin methods:
get_import_form_class()get_import_form_kwargs()get_import_form_initial()get_confirm_form_class()get_confirm_form_kwargs()
For example, to pass extract form values (so that they get passed to the import process):
def get_import_data_kwargs(self, request, *args, **kwargs):
"""
Return form data as kwargs for import_data.
"""
form = kwargs.get('form')
if form:
return form.cleaned_data
return {}
The parameters can then be read from Resource methods, such as:
See also
- Admin
- available mixins and options.
Customize admin export forms¶
It is also possible to add fields to the export form so that export data can be filtered. For example, we can filter exports by Author.
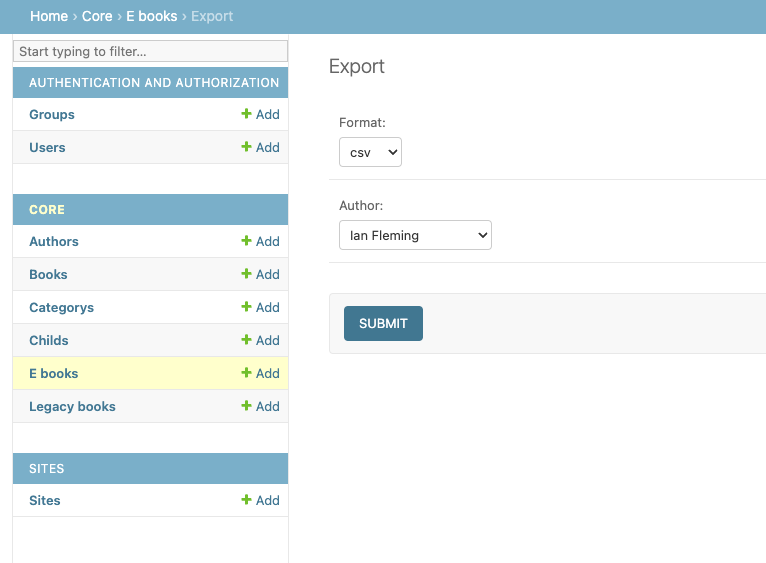
A screenshot of a customized export view.
Customize forms (for example see tests/core/forms.py):
class CustomExportForm(AuthorFormMixin, ExportForm):
"""Customized ExportForm, with author field required."""
author = forms.ModelChoiceField(
queryset=Author.objects.all(),
required=True)
Customize ModelAdmin (for example see tests/core/admin.py):
class CustomBookAdmin(ImportMixin, ImportExportModelAdmin):
resource_classes = [EBookResource]
export_form_class = CustomExportForm
def get_export_resource_kwargs(self, request, *args, **kwargs):
export_form = kwargs["export_form"]
if export_form:
return dict(author_id=export_form.cleaned_data["author"].id)
return {}
admin.site.register(Book, CustomBookAdmin)
Create a Resource subclass to apply the filter
(for example see tests/core/admin.py):
class EBookResource(ModelResource):
def __init__(self, **kwargs):
super().__init__()
self.author_id = kwargs.get("author_id")
def filter_export(self, queryset, *args, **kwargs):
return queryset.filter(author_id=self.author_id)
class Meta:
model = EBook
In this example, we can filter an EBook export using the author’s name.
- Create a custom form which defines ‘author’ as a required field.
- Create a ‘CustomBookAdmin’ class which defines a
Resource, and overridesget_export_resource_kwargs(). This ensures that the author id will be passed to theResourceconstructor. - Create a
Resourcewhich is instantiated with theauthor_id, and can filter the queryset as required.
Using multiple resources¶
It is possible to set multiple resources both to import and export ModelAdmin classes.
The ImportMixin, ExportMixin, ImportExportMixin and ImportExportModelAdmin classes accepts
subscriptable type (list, tuple, …) as resource_classes parameter.
The subscriptable could also be returned from one of the following:
get_resource_classes()get_import_resource_classes()get_export_resource_classes()
If there are multiple resources, the resource chooser appears in import/export admin form. The displayed name of the resource can be changed through the name parameter of the Meta class.
Use multiple resources:
from import_export import resources
from core.models import Book
class BookResource(resources.ModelResource):
class Meta:
model = Book
class BookNameResource(resources.ModelResource):
class Meta:
model = Book
fields = ['id', 'name']
name = "Export/Import only book names"
class CustomBookAdmin(ImportMixin, admin.ModelAdmin):
resource_classes = [BookResource, BookNameResource]
How to dynamically set resource values¶
There are a few use cases where it is desirable to dynamically set values in the Resource. For example, suppose you are importing via the Admin console and want to use a value associated with the authenticated user in import queries.
Suppose the authenticated user (stored in the request object) has a property called publisher_id. During
import, we want to filter any books associated only with that publisher.
First of all, override the get_import_resource_kwargs() method so that the request user is retained:
class BookAdmin(ImportExportMixin, admin.ModelAdmin):
# attribute declarations not shown
def get_import_resource_kwargs(self, request, *args, **kwargs):
kwargs = super().get_resource_kwargs(request, *args, **kwargs)
kwargs.update({"user": request.user})
return kwargs
Now you can add a constructor to your Resource to store the user reference, then override get_queryset() to
return books for the publisher:
class BookResource(ModelResource):
def __init__(self, user):
self.user = user
def get_queryset(self):
return self._meta.model.objects.filter(publisher_id=self.user.publisher_id)
class Meta:
model = Book
Interoperability with 3rd party libraries¶
import_export extends the Django Admin interface. There is a possibility that clashes may occur with other 3rd party libraries which also use the admin interface.
django-admin-sortable2¶
Issues have been raised due to conflicts with setting change_list_template. There is a workaround listed here. Also, refer to this issue. If you want to patch your own installation to fix this, a patch is available here.
django-polymorphic¶
Refer to this issue.
template skipped due to recursion issue¶
Refer to this issue.
Security¶
Enabling the Admin interface means that you should consider the security implications. Some or all of the following points may be relevant:
Is there potential for untrusted imports?¶
- What is the source of your import file?
- Is this coming from an external source where the data could be untrusted?
- Could source data potentially contain malicious content such as script directives or Excel formulae?
- Even if data comes from a trusted source, is there any content such as HTML which could cause issues when rendered in a web page?
What is the potential risk for exported data?¶
- If there is malicious content in stored data, what is the risk of exporting this data?
- Could untrusted input be executed within a spreadsheet?
- Are spreadsheets sent to other parties who could inadvertently execute malicious content?
- Could data be exported to other formats, such as CSV, TSV or ODS, and then opened using Excel?
- Could any exported data be rendered in HTML? For example, csv is exported and then loaded into another web application. In this case, untrusted input could contain malicious code such as active script content.
Mitigating security risks¶
By default, import-export does not sanitize or process imported data. Malicious content, such as script directives, can be imported into the database, and can be exported without any modification.
You can optionally configure import-export to sanitize data on export. There are two settings which enable this:
- IMPORT_EXPORT_ESCAPE_HTML_ON_EXPORT
- IMPORT_EXPORT_ESCAPE_FORMULAE_ON_EXPORT
Warning
Enabling these settings only sanitizes data exported using the Admin Interface. If exporting data programmatically, then you will need to apply your own sanitization.
Limiting the available import or export types can be considered. This can be done using either of the following settings:
- IMPORT_EXPORT_FORMATS
- IMPORT_FORMATS
- EXPORT_FORMATS
You should in all cases review Django security documentation before deploying a live Admin interface instance.
Please refer to SECURITY.md for details on how to escalate security issues.